
밑바닥부터 시작하는 딥러닝 2권을 읽고 필기한 내용들이다.
딥러닝의 기본적인 모델인 RNN과 언어처리에 대하여 배우는 책이였다.
RNN의 기본원리와 CNN과의 차이점, 시계열 데이터인 텍스트 데이터들을 다루는 법을 배웠다. 그리고 RNN을 개선한 다양한 기법들과 공통적으로 일반화 및 성능개선에 도움되는 기법들에 대해 공부하였다.

문장을 벡터로 나타내는 방법 두 가지를 배웠다. 딥러닝으로 사용할 수 있는건 추론기반기법인데 word2vec로 문장을 벡터로 만들어 신경만의 입력으로 사용할 수 있게 한다.
벡터로 바꾸면 동시발생 행렬이라고 주목하는 값만 1이고 나머지는 값이 0인 행렬(one-hot-vector)로 변환한다. 이때 문장의 길이가 길어지면 벡터의 차원이 너무 커지기 때문에 특잇값 분해를 통하여 벡터의 차원을 감소할 수 있음을 배웠다.
추론기반 모델에는 CBOW와 skip-gram 모델이 있는데 CBOW 모델은 학습하는 단어(=타깃) 주변 맥락을 통해 학습한다. 따라서 맥락 갯수와 입력층 노드의 개수는 같다. 이를 개선한 모델이 skip-gram인데 타깃을 입력하여 주변 단어(맥락)을 추론하기 때문에 입력층의 갯수가 적다는 장점이 있었다.
CBOW모델의 개선이다. 입력층과 은닉층으로 나누어 개선방법을 배웠다. 입력층에서는 Embedding이라는 새로운 층을 도입하였는데 이는 문장의 동시발생행렬의 차원이 너무 커질 수 있어 이를 줄이고자 사용하는 계층이다.
원핫벡터와 가중치와의 원핫벡터에서 값이 1인 열과 연산되는, 그 열에 대응되는 가중치의 행만 값이 0이 아니기 때문에 그 행만 추출하는 방식이다.
은닉층에서는 네거티브 샘플링을 이용하였다. 긍정적 예시만을 입력으로 사용한다면 프로그램이 오버피팅 될 수 있기때문에, 자주 보이는 단어들의 틀린 경우를 모아서 예시로 사용하는 경우이다.
새로운 모델인 RNN도 배웠다. 시계열 데이터를 처리할 수 있는것이 특징이고 오차역전파시에 역전파의 연결을 일정하게 끊는것, 배치처리를 위해 Time RNN층을 새롭게 배웠다.
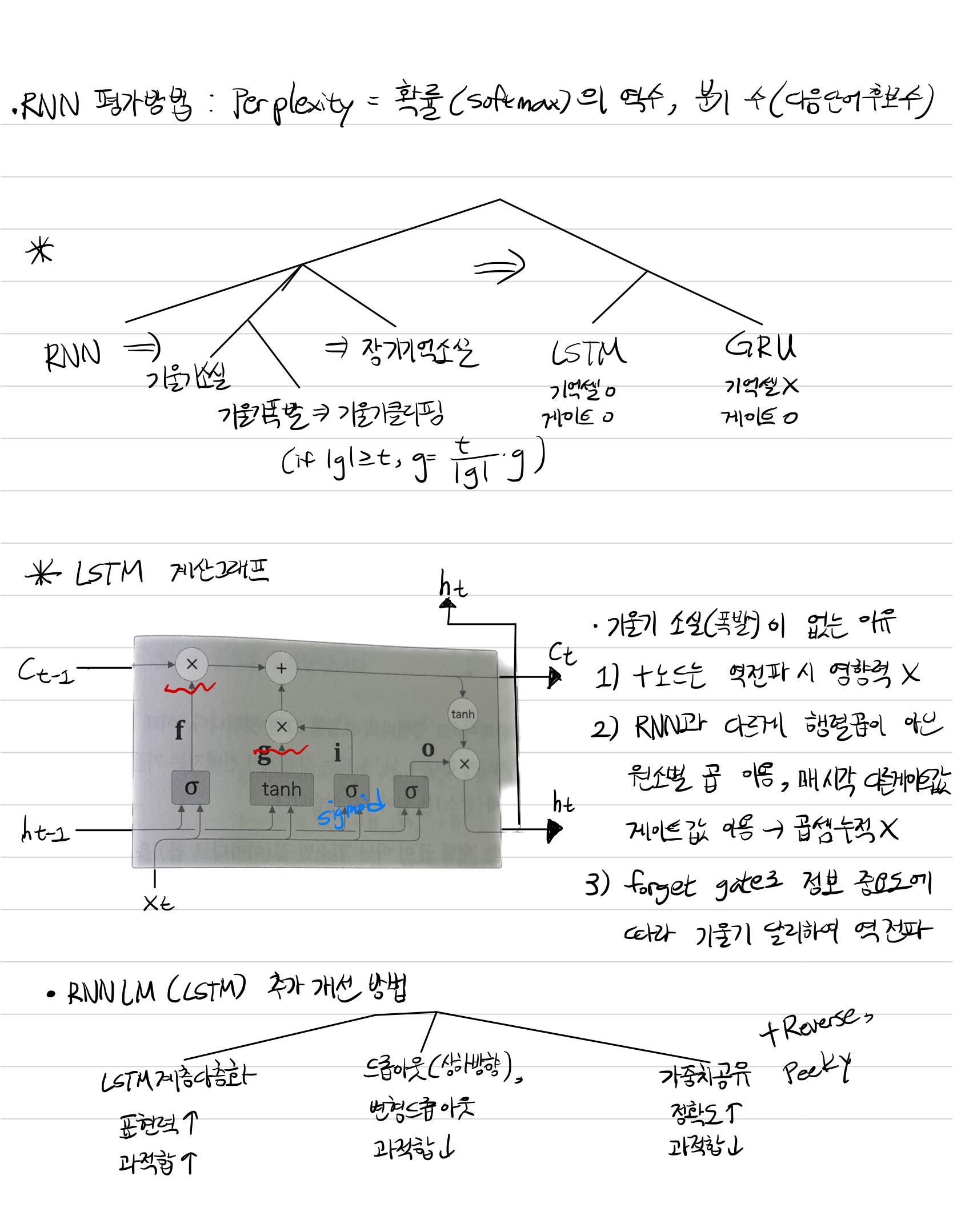
RNN의 성능을 평가할 때는 CNN의 손실함수/정확도와 다른 Perplexity라는 새로운 지표를 사용한다. 확률의 역수인데 한 단어가 등장하면 다음에 등장할 수 있는 단어의 가지수를 의미한다. 따라서 작을수록 좋은 성능을 가진다.
RNN의 개선으로 새로운 모델인 LSTM과 GRU를 배웠다. 일반적으로 RNN이라 함은 LSTM을 의미할 정도로 널리 사용된다 한다. RNN의 문제점은 시계열 데이터가 시간에 따라 길게 입력되고, 따라서 역전파가 길어져 미분값이 커진다는 것이다. 기울기 폭발은 기울기 클리핑이라는 방식으로 방지할 수 있지만, 일반적으로 대응할 수 있는 LSTM이나 GRU를 선호하는듯 하다.
GRU는 목차로 따로 설명하고 있고 LSTM부터 배웠는데 LSTM은 RNN과 다르게 기울기 소실, 혹은 폭발이 일어나기 힘들다는 장점이 있다. 왜냐면 매 시각 다른 게이트값을 이용해서 역전파 계산을 수행하기 때문에 역전파가 누적이 되지않기 때문이다.

RNN(LSTM)을 응용한 것으로 번역기, 문장 생성이 있다. LSTM을 두개 연결해서 입력단은 encoder, 출력단은 decoder라고 부른다. encoder의 개선으로 입력의 길이를 가변으로 변경하는 것이다. 이를 통해 입력벡터의 크기가 과도하게 커지는 것을 방지 할 수 있었다.
Decoder의 개선으로는 중요한 기법을 배웠다. Attention이라는 계층인데, Attention weight 계층과 weight sum계층으로 나뉜다. 먼저 Attention weight계층에서 weight sum계층에 넘겨줄 가중치 a를 구한다. 이 가중치 a는 Encoder의 출력과 LSTM의 은닉벡터를 내적하여 구한다(Attention weight계층은 LSTM 다음 계층). 왜냐하면 내적을 통해 벡터의 유사도를 구할 수 있기 때문이다.
다음으로 Weight sum계층에서 가중치 a와 Encoder의 출력을 합계산한다. 이렇게 되면 기존 LSTM과 다르게 Attention계층을 출력하면 Encoder의 출력을 Decoder의 시각대의 층이 받을 수 있게 된다.
마지막으로 LSTM의 개선방법을 다양하고 간략하게 배웠다. 양방향 LSTM, skip 연결, self attention, NTM이 그것이다.
'AI' 카테고리의 다른 글
| Identifying and attacking the saddle point problem in high-dimensional non-convex optimization 리뷰 (0) | 2022.09.20 |
|---|---|
| 손실함수의 그래프(Training Curve, Loss Landscape)와 최적화 방법 (0) | 2022.09.20 |
| Visualizing the Loss Landscape of Neural Nets 리뷰 (0) | 2022.09.19 |
| 밑바닥부터 시작하는 딥러닝①: 손실함수와 정확도 미분 (0) | 2022.09.16 |
| 밑바닥 부터 시작하는 딥러닝① 요약 (0) | 2022.09.16 |