
딥러닝을 공부한지 두달정도가 지났고 딥러닝계의 바이블로 불리는 '밑바닥부터 시작하는 딥러닝①'로 시작하였다.
신경망(ANN)의 기초와 평가방법, 최적화 그리고 합성곱계층(CNN), 오버피팅 방지 등에 대해 배우는 책이였다.
책을 공부하며 정리한 요약본을 남겨본다. 책을 읽으며 생긴 의문점과 그에 대한 답은 후속 포스트에 남겨놓았다.

신경망에 대해 처음 배우는 장이다. ANN, 완전연결계층과 입력(label)을 이용해 머신러닝의 기초에 대하여 배웠다.
ANN은 입력층, 은닉층, 출력층으로 나눌 수 있었고 층의 깊이를 깊게 할때는 은닉층을 깊게 쌓았다.
입력층에 데이터를 바로 입력하지 않고 데이터의 특성들을 고려하여 전처리 후, 입력하면 정확도를 더 높힐수 있었다.
모델을 평가할 때는 정확도와 손실함수라는 지표를 사용하는데 손실함수를 사용해야 역전파때 미분값이 연속적으로 변하기 때문이다.
매개변수 최적화 방법으로는 4가지를 배웠다. 각각 SGD, 모멘텀, AdaGrad, Adam이다. 최신연구에서도 Adam을 사용하는 것을 볼 수 있었다.
가중치 초깃값도 np.rand를 이용하여 무작위로 설정할 수 있지만, Xavier나 He값을 사용하면 갱신이 더 잘되는 것을 볼 수 있었다.
마지막으로 일반화 능력을 올리기 위해서(오버피팅 방지) 쓰는 스킬인 드롭아웃과 가중치 감소에 대해 배웠다. 가중치 공유또한 도움이 되겠다.
전반적으로 모델의 종류에 대해서 배우기보단 모델의 성능을 끌어올리는 방법에 대해 배우는 장이였다.
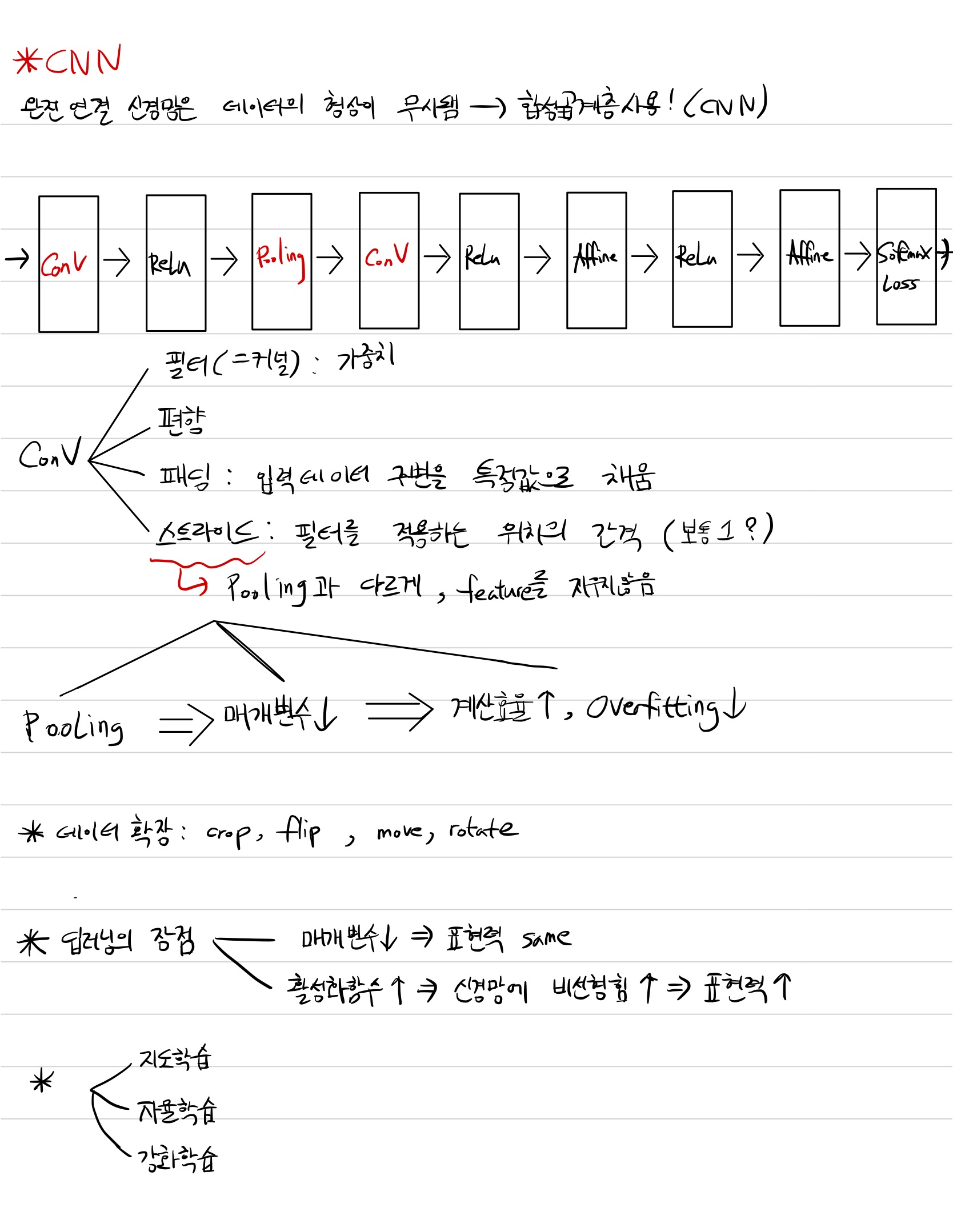
마지막으로 새로운 모델인 CNN에 대하여 배웠다. 데이터의 형상을 유지하기 위하여 고안된 모델이라 한다. Convolution연산을 하기 때문에 CNN이라 불린다.
CNN의 구조에 대하여 배웠고 Convolution 연산을 한 후엔 활성화 함수를 거치고, 차원감소를 위하여 pooling을 사용할 수도 있고 사용 안할 수도 있다.
Stride와 Pooling 둘 다 데이터의 차원(형상)을 줄이는 메소드라 생각하여 차이에 대하여 궁금해서 좀 찾아보았는데, Stride는 Pooling과 다르게 데이터의 특징이 지워지지 않는다 한다.
'AI' 카테고리의 다른 글
| Identifying and attacking the saddle point problem in high-dimensional non-convex optimization 리뷰 (0) | 2022.09.20 |
|---|---|
| 손실함수의 그래프(Training Curve, Loss Landscape)와 최적화 방법 (0) | 2022.09.20 |
| Visualizing the Loss Landscape of Neural Nets 리뷰 (0) | 2022.09.19 |
| 밑바닥 부터 시작하는 딥러닝② 요약 (0) | 2022.09.18 |
| 밑바닥부터 시작하는 딥러닝①: 손실함수와 정확도 미분 (0) | 2022.09.16 |