
1. Intro
딥러닝을 처음 접하는 사람들의 통념과는 다르게 전통적인 머신러닝 기법들이 더 높은 예측성을 보이는 경우들이 있다.
특히 Decision Tree는 노이즈가 많은 데이터, 정형데이터 등에서 강점을 보이는데 공모전에서 그러한 데이터들을 다루기 위해 LightGBM을 사용하였고 이를 사용하기 위해 공부한 내용들을 bottom-up방식으로 정리해보고자 한다. Decision Tree에 대해 간략하게 알아보고 이를 개선한 Bagging, Boosting에 대해 살펴보겠다. Bagging과 Boosting의 개선판인 Random Froest, Gradient Boosting에 대해 다룬 후 Gradient Boosting의 개선판들에 대해 정리해보겠다.
2. Decision Tree
Decision Tree는 머신러닝뿐만 아니라 다른 분야에서도 사용되는 도구로 데이터들을 분석하여 패턴을 만드는 기법으로 나무와 같이 생겨 의사결정나무라 부른다. 머신러닝에서 Decision Tree는 Regression과 Classification 모두에서 사용가능하다.

캐글의 가장 기초적인 타이타닉 생존자 예측문제를 임의대로 Decision Tree로 나타내 보았다. 독립변수는 생사여부가 될 것이고 종속변수는 성별, 나이 그리고 좌석등급 등이 된다. 이렇게 Decision Tree는 종속변수와 독립변수의 관계를 설명할 수 있고 딥러닝과 다르게 Whitebox로 흐름을 알 수 있고 결과를 해석할 수 있는 것을 볼 수 있다.
Binary Data는 이분법적으로 나뉘고 Discrete Data는 category개수만큼, continuous data는 특정숫자를 기준으로 분기하게 된다.
2.1 Cost Function
Decision Tree의 학습과정에 앞서 Decision Tree의 평가지표에 대해서 먼저 알아보겠다. Decison Tree는 Information Gain가 클수록, homogeneity는 커지고 uncertainty는 작아질수록 좋은 모델이라 평가한다. 이를 위한 지표로 Entropy, Gini index를 사용한다. 이 지표를 사용하여 Decision Tree는 Entropy, Gini index가 작아지는 방향으로 학습한다.
2.2 Training
다음으로 Decision Tree는 어떤 방식으로 학습을 하고 어디서 분기할지를 정하는지에 대해 알아보겠다.
먼저 Decision Tree는 학습 시 Recursive Binary Splitting와 pruning방식으로 학습한다.
Recursive Binary Splitting은 recursive partitioning라고도 부르며 먼저 종속변수들 중 하나를 선택해 정렬 후 분기점을 만든다. 위의 타이타닉 예시에서 종속변수는 성별, 나이 그리고 좌석등급이다. 따라서 첫 분기점으로 3가지 경우의 수가 있다. 만약 종속변수가 연속형변수라면 각각의 값들에 대하여 분기점을 다시 만들고 평가지표를 사용하여 제일 좋은 경우의 수를 고른다. 그 후 다음 분기점으로 다시 2가지 경우의 수에 대해 계산하는 식이다. 따라서 Decision Tree는 Top-down 방식의 Greedy Algorithm을 이용해 학습한다.
Pruning은 가지치기라는 뜻으로 분기를 합치는 기법이다. Pruning에는 여러 방식이 있는데 leaf부터 분기를 합치는 reduced error pruning이 있고 정확도가 더 높은 cost complexity pruning이 있다. cost complexity pruning는 cost function으로 CC(T)= Err(T) + α*L(T)를 쓴다. cost function이기에 CC(T)값이 낮을수록 좋으며 Err(T)는 검증데이터에 대한 오분류율이고 L(T)는 노드의 개수이다. α는 가중치로 sub-tree의 개수에 따라 노드를 합칠지 말지를 결정한다. Pruning을 함으로써 모델의 복잡도가 낮아져 overfitting을 줄이고 모델의 예측력, 정확도를 높힐 수 있다.
이렇게 간략하게 Decision Tree는 어떻게 학습을 하는지, 학습할 때 평가지표는 무엇을 쓰는지에 대해 알아보았다. 다음 chapter에서 Decision Tree를 활용하여 더 높은 예측성을 가지는 기법인 Ensemble에 대해 알아보겠다.
3. Ensemble
Ensemble의 종류와 그 특성에 대해 Figure2에 간략하게 정리해보았다. Ensemble 학습은 여러 개의 Decision Tree를 결합하여 예측력이 좋은 모델을 만드는 기법이다. 즉, Emsemble 학습은 여러개의 약 분류기(Weak classifier)를 결합하여 강 분류기(Strong classifier)를 만드는 것이다. Ensemble학습에는 두가지 종류가 있다. 각각 Boosting과 Bagging이다.
3.1.1 Bagging
Bagging은 bootstrap aggregating의 줄임말로 Meta Learning의 한 종류이다. Bagging은 학습 시 복원 표본추출을 이용해 training dataset들을 생성한다. 이 training dataset들은 복원 표본추출을 통해 추출했기에 중복되는 값들이 존재하고 따라서 이러한 training datset들은 bootstrap이다. 각각의 dataset으로 모델을 학습한 후 학습의 목적에 따라 Regression이면 모델들을 평균내서 하나의 모델을 만들고 Classification이면 투표로 모델을 만든다. 각각의 모델들(Weak classifier)들이 서로 독립적으로 결과를 예측한다는 특징이 있다.
3.1.2 Random Forest
랜덤포레스트는 배깅을 이용한 알고리즘인데 Bagging에 각 training datset에 서로 다른 feature들이 들어가도록 하는 feature randomness를 더해 서로 상관관계가 매우 낮은 decision tree들로 forest(하나의 모델)을 만들어 ,overfitting과 편향을 줄여 더 예측력이 좋은 모델을 만들 수 있다.
3.2.1 Boosting
Boosting역시 약 분류기들을 결합하여 강 분류기를 만드는 기법이지만 Bagging과 다르게 약 분류기들이 Sequential하게 결합되어 있어 이전의(t-1) 약 분류기의 결과에 가중치를 곱하여 다음의(t) 약 분류기에 전달된다. Boosting에는 Adaptive Boosting, Gradient Boosting등이 있는데 이 글에선 주로 쓰이는 Gradient Boosting에 대해서만 다룬다.
3.2.2 Gradient Boosting
먼저 Gradient Boosting에서 회귀 모델을 만들 때 학습 과정을 그래프를 통해 이해해 보자.
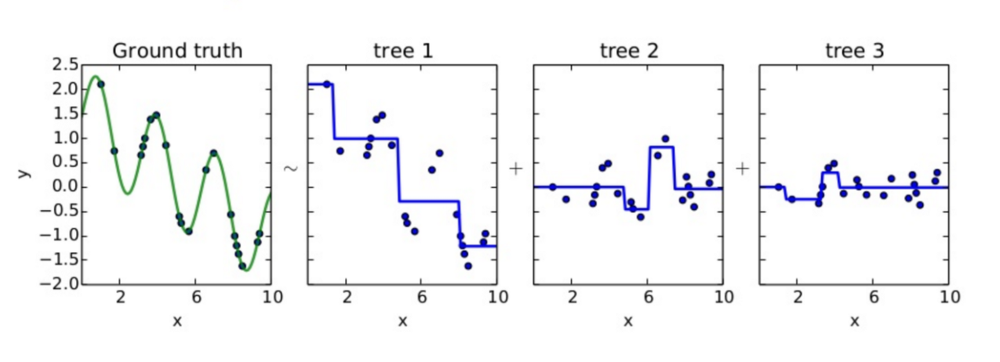
Ground truth는 data들에 대해 우리가 원하는 모델의 모습이다. 분류기인 tree1을 보면 모델에 residual이 존재하는 것을 볼 수 있다. Residual은 실제 데이터와 예측한 결과의 차이이기에 tree1의 residual들에 대하여 tree2에서 다시 학습을 하고, 그 residual에 대하여 다시 tree3가 학습을 하는 모습을 볼 수 있다. 각각의 tree들을 합쳐서 Ground truth를 만드는 기법이 Gradient Boosting기법이다.
Residual을 다음 모델에 전달해 학습하는데 왜 Gradient Boosting이라 하는지 이해가 안될 수 있다. 이는 loss function이 sqaured error라면 loss function의 미분에 -1를 곱한값은 residual과 같기 때문이다. loss를 최소화 시키는 방법은 loss를 loss function의 미분값의 방향으로 움직이는 것이기 때문에 미분값에 -1을 곱한값과 같은 residual을 출력에 더한다면 loss는 감소할 것이다.(SGD를 생각해보자) 따라서 이를 Gradient Boosting이라 한다.
물론 loss function이 꼭 squared error인 것은 아니다. 예를 들어 위의 예시처럼 sqaured error는 회귀 모델을 구할 때 쓰는 loss function이지만 분류 모델을 구할 때는 cross_entropy 등 다른 loss function을 쓸 것이고 물론 이때도 negative gradient를 이용해 loss를 줄일 것이다.
3.3.1 Improvements of Gradient Boost
마지막으로 Gradient Boost의 개선판인 XgBoost, LightGBM, CatBoost에 대해 알아보겠다. 서술순서는 먼저 나온 Algorithm부터 시간순으로 서술하겠다. AdaBoost는 가장 위의 세 Algorithm보다 먼저 나왔지만 최근에 잘 쓰이지 않아 제외한다.
3.3.2 XgBoost
먼저 XgBoost이다. XgBoost는 Pruning에 개선을 해 max_depth라는 parameter로 최대 깊이를 제한함으로써 학습 속도에 향상을 가져왔다. 최대 깊이부터 Information gain이 음의 값인 분기들을 합치는 방식으로 pruning한다.
또한 OpenMP API를 이용해 병렬연산을 지원함으로써 학습속도를 빠르게 하였다. 물론 Gradient Boosting은 tree들이 서로 sequential하기에 Random Forest처럼 각각의 모델을 병렬로 만들지는 못하지만 하나의 tree에서 가지들을 병렬적으로 만들고 가지를 만들기 위해 feature들을 정렬할 때 병렬처리를 하여 분기점들의 경우의 수를 병렬적으로 연산케 한다.
그리고 결측치가 있어도 학습이 가능한데 이는 각 분기점마다 loss가 감소하는 값으로 채워진다.
3.3.3 LightGBM
다음으로 LightGBM이다. LightGBM은 leaf-wise (best-first)방식으로 가지를 늘린다. level-wise방식과 다르게 불균형하게 가지가 늘어나기에 데이터의 크기가 작을 때 overfitting이 일어나기 쉽다.
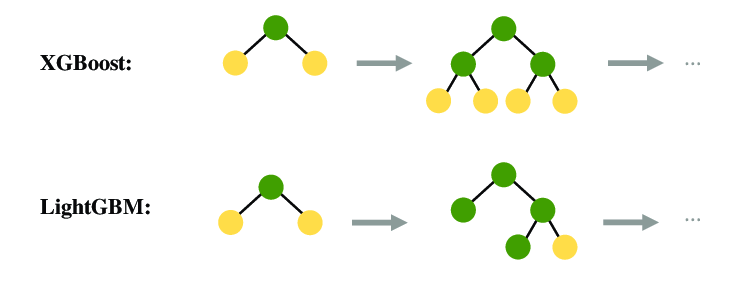
Figure4의 위쪽 그림이 level-wise방식이고 아래 그림이 leaf-wise방식이다. 현재는 XgBoost도 leaf-wise방식을 지원한다.
LightGBM은 XgBoost와 동일한 방식으로 결측치를 처리하는데 loss가 제일 작을 값으로 결측치를 채운다.
또한 XgBoost와 다르게 Categorical feature를 처리하는 방법이 있는데, Category들을 2개의 부분집합으로 나눈 후 분기할때 마다 독립변수에 따라 정렬하여 분기시키는 방식이다. 다만 정수형으로 변환해야 코드로 돌릴 수 있다.
그리고 이름으로도 알 수 있듯이 LightGBM은 빠른속도가 장점인데 GOSS와 EFB라는 새로운 Algorithm으로 이를 가능케 한다.
GOSS는 학습 시 gradient가 큰 feature들에 집중하여 학습할 수 있도록 gradient가 작은 feature들은 random sampling 후 분포를 유지하기 위해 보정을 취해 학습이 덜 된, gradient가 큰, feature들에 집중하여 학습속도를 빠르게 하는 방법이다. 학습이 덜 된 feature들에 집중하므로 정확도또한 향상된다는 장점이 있다.
EFB는 학습속도 향상을 위해 고안된 Algorithm으로 상호배타적인 feature들을 묶고, offset을 더함으로써 상호배타적인 feature들을 만들어 내 feature의 개수를 줄이는 방식으로 학습속도의 향상을 가져온다.
LightGBM의 원리에 대해 조금 더 자세히 쓴 글은 여기에 있다.
3.3.4 CatBoost
마지막으로 CatBoost이다. CatBoost는 Categorical Boosting의 약자이다. 이름에서 알 수 있듯이 Category data를 다루기 좋은 Algorithm인데 one-hot-encoding과 advanced mean coding 두 방법을 합쳐서 쓴다. one-hot-encoding은 category의 개수가 클 경우 차원이 너무 커져 메모리가 감당 못할수 있다는 단점이 있다. 이를 해결하기 위해 CatBoost에서는 one-hot-encoding시 할당 할 최대숫자를 parameter로 지정할 수 있고, 남은 값들은 advanced mean coding을 이용해 처리한다.
결측치는 위의 두 Algorithm과 다르게 결측치를 최소 혹은 최대값으로 채운다.
마지막으로 CatBoost도 LightGBM처럼 sampling을 통해 속도와 정확도 향상을 이루었는데 Minimal Variance Sampling (MVS)라는 sampling방법을 사용했다. 이는 Random Gradient Boosting에 가중치를 더해 sampling하는 방식이고 tree를 만들 때 행해진다.
4. Conclusion
이번 포스트에선 Decision Tree부터 Bagging, Boosting 그리고 이들의 발전버전인 Random Forest와 Gradient Boost에 대해 살펴보았다. 여전히 많이 사용되고 있는 기법들이고 머신러닝 기법중 하나인 Decision Tree에 대해 이해력이 높아지는 계기가 되었고 이 글을 읽는 분들도 약간의 도움이 될 수 있기를 바랍니다.
만약 부족하거나 틀린 부분이 있다면 댓글로 남겨주시면 반영할 수 있도록 하겠습니다. 감사합니다.
5. Reference
https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
https://en.wikipedia.org/wiki/Decision_tree
https://ratsgo.github.io/machine%20learning/2017/03/26/tree/
https://en.wikipedia.org/wiki/Ensemble_learning
https://www.ibm.com/cloud/learn/random-forest
https://3months.tistory.com/368
https://towardsdatascience.com/why-is-boosting-fitting-residual-9ac6f4e77550
https://statinknu.tistory.com/33
https://aws.amazon.com/what-is/boosting/?nc1=h_ls
Guolin Ke et al. (2017). LightGBM: A Highly Efficient Gradient Boosting Decision Tree. NeurIPS Proceedings
'AI' 카테고리의 다른 글
| LightGBM GPU 사용방법 (Linux, window) (0) | 2022.10.13 |
|---|---|
| LightGBM: A Highly Efficient Gradient BoostingDecision Tree (0) | 2022.10.11 |
| 모델 학습 시 데이터를 shuffle해야 하는 이유(배치 학습) (0) | 2022.10.04 |
| 캐글 타이타닉 생존자 예측 실습(Logistic Regression) (0) | 2022.09.28 |
| Attention Is All You Need 리뷰 (0) | 2022.09.22 |